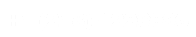Health Data Management and Knowledge Discovery Case Solution
Problem Statement
The statement of purpose shows the relevant importance of analyzing the health and knowledge discovery management data by determining different variables that are linked with each other with regards to the impact on the related classes (Independent Variable). The key problem of such process is the lack of relationships of various forms of variables over the health and patient performance. Therefore, analysis can be performed through the use of Wake to determine the relationships between each other under the concept of J 48 algorithm and discretionary of data set.
Literature Review
According to the study of Azazel ET. Al (2012), the data consisted of the use of Non-communicable form of diseases that were considered to be the biggest killers under the health perspective. With the use of web data mining process, the results indicated the expected deaths of people with more ratio in the future and that would incur in developing countries. In contrast to the data analysis, Hirsute ET. Al (2013) analyzed the literacy rate of the inequalities of the male and female by the use of Wake as the main tool to generate the results.
The outcome of the values were more favorable to males as compared to females. Thus, it was determined that use of Wake would be a predicted outcome of the expected happenings of the results, not the actual to be implemented. Another study of Madurai eternal (2013) compared the performance of healthcare sectors. The results showed that by the use of data mining tools, an expected outcome would be achieved and could be implemented in the future.
Design & Methods
Under the given scenario, it has been determined that the data is collected from the health management and knowledge discovery. It consists of various forms of data like blood pressure, age, sex etc. However, in order to design the impact of one variable over another, the use of Weak would allow to generate the results that would be suitable to analyze an expected outcome.
On the certain level of variables, class is considered to be an independent variable, whereas all other data will be utilized as dependent variables. Class is identified as the main source to generate the results because it analyzes the level of patients to conclude the treatments and other forms of facilities. All other variables like age, sex, and blood pressure are directly proportional to the level of class being utilized.
The most popular use of data extraction that is discretionary method has implemented to generate the variables into different forms of values in order to determine the individual results of each variable over the other. The same scenario is applied to implement the results, which is to fix the Class as independent variable and relate to the others treated as dependent variables. Excluding the Class, there are eight forms of samples considered as dependent variables to apply the study of Wake.
Health Data Management And Knowledge Discovery Harvard Case Solution & Analysis
Results
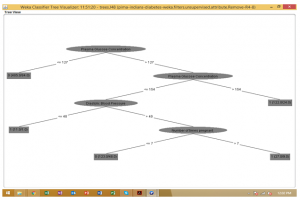
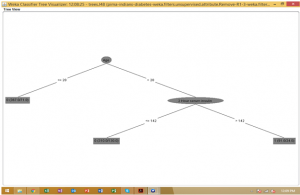
From the following results, it is concluded that j 48 algorithm method is used to determine the relevant accuracy and errors of the certain variables with relationship to the Classes. Moreover, three samples have been included to analyze and relate the data with the others. Under the result of the first sample, it seems that the total absolute error within the certain outcome is 35.97%, whereas the second sample performed 30.57% of absolute error. In the case of the third sample,the values show 39.73% of error subjected to the absolute one. In addition to that, the visualization of decision tree is analyzed with the use of Wake, which shows the roots of variables performing in collaborative way. Therefore, with all these concerns, it can be said that the results would provide relevancy on how to determine the impact of one variable over another.
This is just a sample partial case solution. Please place the order on the website to order your own originally done case solution.
Related Case Solutions & Analyses:
 Omnitel Pronto Italia
Omnitel Pronto Italia
 Taran Swan at Nickelodeon Latin America (A)
Taran Swan at Nickelodeon Latin America (A)
 Newell Co.: Corporate Strategy
Newell Co.: Corporate Strategy
 The California Global Warming Solutions Act (AB 32)
The California Global Warming Solutions Act (AB 32)
 Coca-Cola and Huiyuan (A): Antitrust Barriers to Buying Top Chinese Brands
Coca-Cola and Huiyuan (A): Antitrust Barriers to Buying Top Chinese Brands
 HP at a Strategic Crossroad: 2005
HP at a Strategic Crossroad: 2005
 Stevenson Industries (C)
Stevenson Industries (C)
 Just-in-Time Production Controlled by Kanban
Just-in-Time Production Controlled by Kanban
 GE’s Imagination Breakthroughs: The Evo Project, Video
GE’s Imagination Breakthroughs: The Evo Project, Video